Parallelism
| Parallelism | batch dim | sequence dim | hidden dim | weights | optimizer |
|---|---|---|---|---|---|
| DP | √ | ||||
| TP | √ | √(intra-layer) | |||
| Ring Attention | √ | ||||
| PP | √(intra-layer) | √ | |||
| ZeRO | √ | √ | |||
| FSDP | √ | √(intra-layer) | √ |
Model Parallelism
- Intra-Operator: partitions computationally intensive operators, such as matrix multiplications, across multiple GPUs, accelerating computation but causing substantial communication.
- Inter-Operator: organizes LLM layers into stages, each running on a GPU to form pipelines.
DP
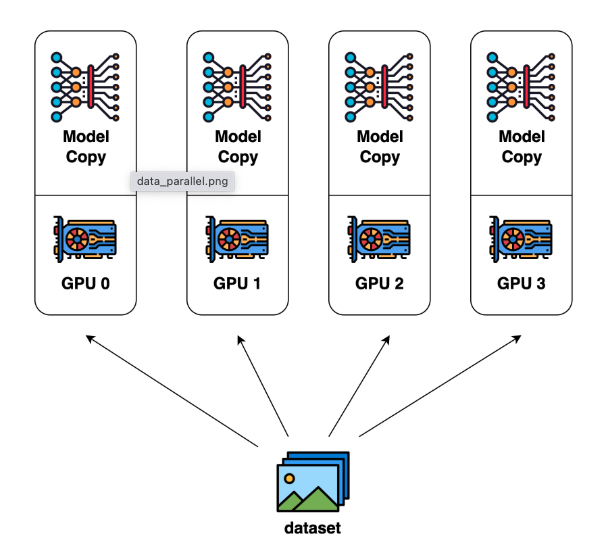
Data Parallelism is most common due to its simplicity:
the dataset is split into several shards, each shard is allocated to a device.
TP
Tensor Parallelism:
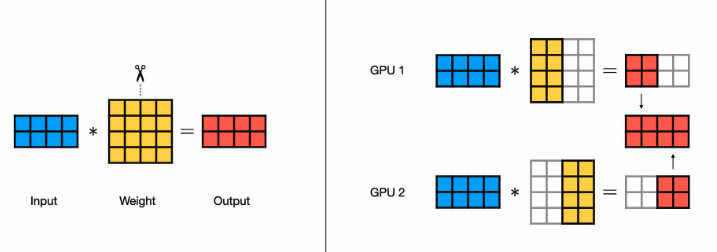
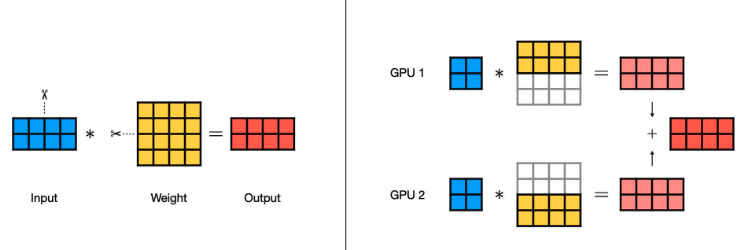
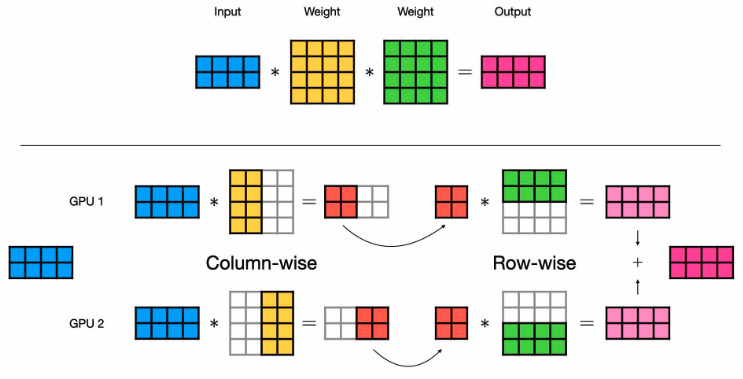
Collective communications involve network-intensive operations are required after the operation.
Operations
- AG (AllGather): column-wise
- AR (AllReduce): row-wise
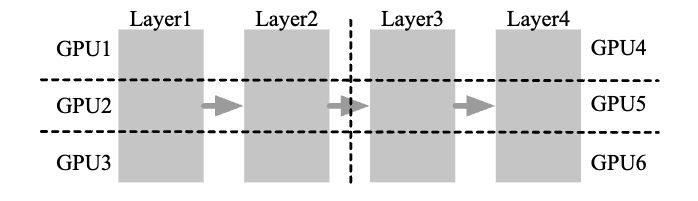
PP
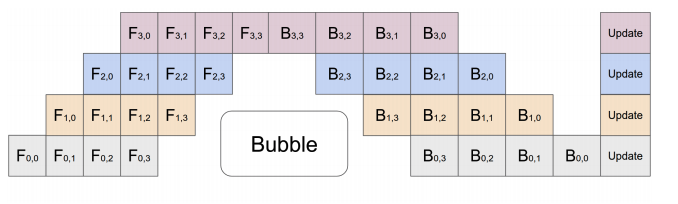
the model is split by layer into several chunks, each chunk is given to a device
During the forward pass, each device passes the intermediate activation to the next stage. During the backward pass, each device passes the gradient of the input tensor back to the previous pipeline stage.
Device with PP operates on mirco-batch split by stages.
EP
Expert Parallism
Batching
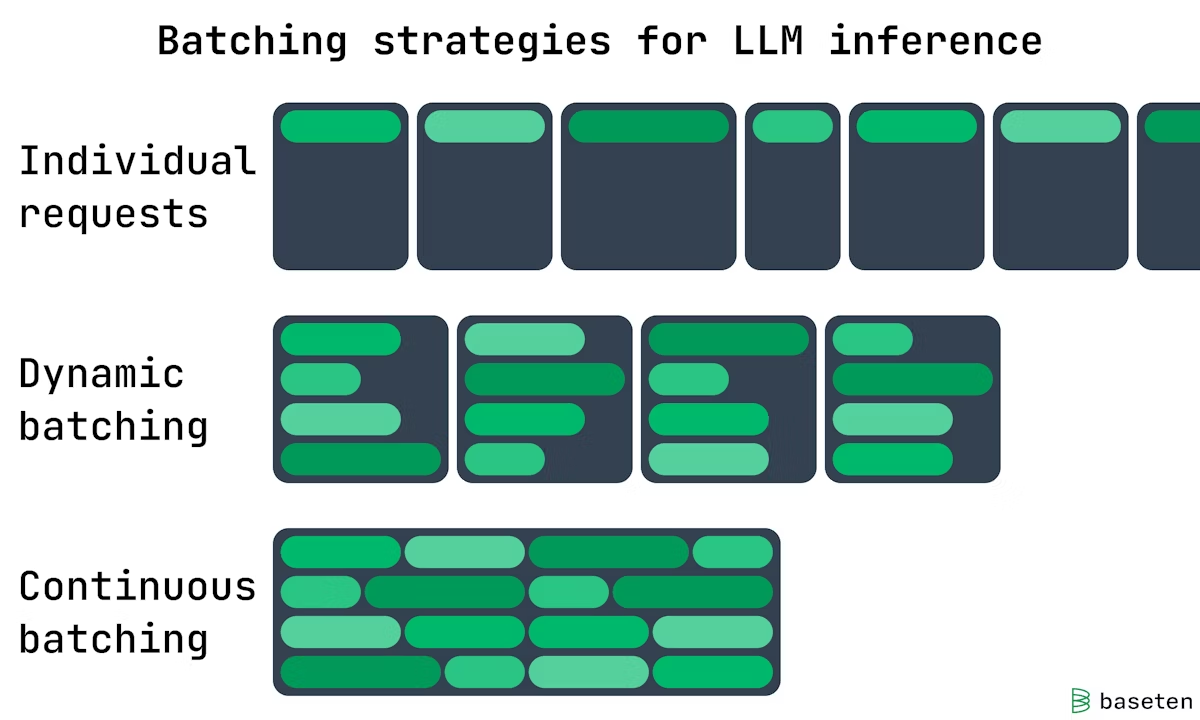
- Continuous Batching: continuous and dynamic gpu memory
- Static Batching: create static gpu memory for each request
batch size: how many user inputs are processed concurrently in the LLM.
metrics
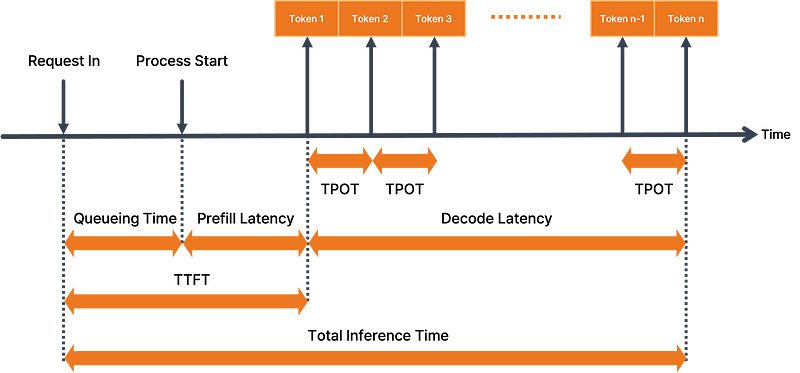
- ttft (Time to First Token)
- tpot (Time Per Token Output)
- e2el (End to End Latency)
- MBU (Model Bandwidth Utilization):
- (achieved memory bandwidth) / (peak memory bandwidth)
- achieved memory bandwidth = ((total model parameter size + KV cache size) / TPOT)